

Methodology – Review Biases and Limitations
All methods have their inherit limitations. The advantage of the statistical approach adopted here is that it allows you to measure the degree of confidence in the outcome of the analysis. As we saw on my previous Understanding Reviewer Scoring, there are a number of differences between reviewers that have to be faced before we can construct a statistically-valid Meta-Critic score.
My intention is not to bore you with the detailed math, but to pull back the curtain enough so that you can see why it is valid (and necessary). To do that, I need to step back a bit, with a discussion of the main barriers, biases and limitations in the source data I am dealing with – the opinions of expert reviewers.
Expert Reviewers vs Crowd-Sources Commentaries
The first question you might ask if why even start with self-identified “experts”? Shouldn’t the democratization of the internet allow everyone’s opinion to be included in the analysis? After all, there are plenty of user commentaries on the major whisky sale sites, plus opinions on the established blogs and review sites. And isn’t one person’s opinion as good as any other, if all our tastes are subjective?
The short answer is no. 🙂
The longer answer has to do with some basic tenets of human psychology, as well as the needs for consistency and independence in statistical analyses.
Personally, I often find the online commentaries section on reviews interesting to read – they can certainly provide some stimulating ideas. But fundamentally, you need to be critical when assessing commentaries that come from someone who has bought the product in question with their own money. Now, you might think that personal purchasing would be a good thing – it removes any bias from having review samples supplied. But people who post online with their unsolicited opinions on their own purchases tend to rank them higher than those who are trying to provide a dispassionate assessment of all available products.
The reason for this it that we all tend to justify our own decisions (i.e., I did my research, picked this product, therefore this product must be good!). This bias only goes up as the perceive luxury or dollar value of the product increases. This is why customer satisfaction surveys of new vehicles, for example, are meaningless (i.e. “98% of purchasers of the fill-in-the-blank-vehicle report extremely high satisfaction within 30 days of purchase”). No kidding – since the car is unlikely to break down in the first month of ownership, the purchase bias remains alive and strong.
User Commentaries
The same basic principle applies for whisky. In preparing for this analysis, I have explored many “whisky expert” sources, most especially reviewers who have published many hundreds or thousands of individual whisky reviews (their poor livers!). I noticed that many of the comments from readers on individual review pages tend to follow a stereotypical pattern. These typically begin with (often effusive) praise for the reviewer’s genius in scoring a particular whisky highly (and let’s face it, most online reviews tend to be fairly positive of their subject matter). Again, the purchase bias is alive and kicking here, since readers like to toss their support behind whiskies they have bought and enjoyed (i.e., herd effect). If you don’t believe me, watch the fur fly when a reviewer posts a negative review of a popular product – I can guarantee the comments threads will be extensive (and potentially highly entertaining).
But pretty soon, the next thing that happens are comments along the following lines: “sure, this whisky X is ok, but in my experience whisky Y is a far superior product.” And the purchaser bias rears its ugly head once again. On what basis is that quasi-anonymous user comment drawn? A wide experience of a hundred whiskies? Unlikely. A dozen whiskies? Maybe. Two whiskies? A distinct possibility. Put that in context to the established reviewer who has taken the time to do a detailed assessment, with presumably some attempt at standardization. And the advantage is that his/her full catalogue of reviews is open for everyone to see, warts and all. Not having that to assess on some random commentator, whose opinion seems more trustworthy as a starting point for further analysis?
Another common bias in these commentaries is the one of perceived value for money (i.e., “sure this fancy $200 bottle is good, but I know of this $20 bottle that is even better”). Honestly, this comes up so often (sometimes in laughably mismatched flavour categories to the original review) that I sometimes wonder if the poster has even sampled the review bottle in question – or is just using this as an opportunity to flog their own personal budget hobby horse throughout the internet.
To be sure, there are many excellent comments out there, and sites that seem to do some attempt at moderation. My point above is not to disparage all online commentaries, but simply to point out the biases behind them can be hard to detect on casual glance. And let’s face it, internet trolls abound. It’s easy to fire off a quick epistle with a “yay” or “nay” on someone else’s thoroughly crafted review, and make it sound like you are just as knowledgeable or experienced as the reviewer (without providing any evidence to back that up).
Just in case you think I’m unfairly dismissing user commentaries, please see my Reviewer Selection page for some comments around underlying biases to be aware of there too.
Ultimately though, quasi-anonymous user comments pose an insurmountable problem when it comes to assessing quality and consistency – unless individuals can be identified who have an extensive comments catalogue to examine (in which case, they essentially become an expert reviewer in their own right). Ultimately, it is impossible to properly normalize one crowd against another crowd without information as to their specific biases. This is only feasible to achieve with established reviewers where their detailed catalogue is easily accessible.
I don’t want to brush off all user commentary sites here – there are large, dedicated user communities (aka, discussion forums) that can be excellent and quite relevant in helping you assess whisky quality. I discuss just such an example in more detail in this post.
As an aside, there is one potential advantage to using a very large dataset of user ratings over the small expert panel ranking method used here – you could use a proper Bayesian estimator. Popular in estimation/decision theory, a Bayes estimator is used to compensate for when only a small number of ratings are available on any given item in a much larger dataset (i.e., what is known as posterior expected loss). It works nicely across extremely large datasets that have highly variable numbers of reviews (e.g., the Internet Movie Database apparently uses a Bayesian estimator). Items with a low number of reviews are given lower weighing in the analysis. Once the number of ratings reaches a defined threshold, the confidence of the average rating surpasses the confidence of the prior knowledge, and the weighted Bayesian rating essentially becomes a regular average.
But the problem of lack of independence among reviewers still persists in these cases. And it doesn’t really apply for the relatively small expert panel used in this analysis. Instead, you can leap ahead to my Interpretation pages, where I discuss the simpler cut-off values I use for low number of reviews.
Sources of Variation
In any case, this gives us our first chance to review some actual data. In my previous post on Understanding Reviewer Scoring, I explained the general framework most reviewers seem to use – and how variable it actually turns out being in practice. As a product reviewer in the flashlight field, I have personally avoided using this approach (since it ties you to a scale that you can never change). But it is common among whisky reviewers, so let’s go further down the rabbit hole to see where it leads us.
I will get into the detailed Meta-Critic scoring methodology shortly. But for now, let’s do a simple analysis and comparison of some of the reported scores for the whiskies in my master analysis dataset, as introduced in the last article.
Visual Presentation of Key Descriptive Statistics
I am going to show this graphically, using what is known in the stats biz as a box-and-whiskers plot. Box-and-whiskers plots allow you to easily see the variation among samples of a given statistical population (without making any assumptions of the underlying distribution). The spacings between the different parts of the box indicate the degree spread and skewness in the dataset.
In essence, this is a refined version of the simple distributions that I showed previously, incorporating some key descriptive statistics of the distributions in a graphical way.
A box-and-whiskers plot takes the following form (turned sidewise blow to better illustrate the various components):
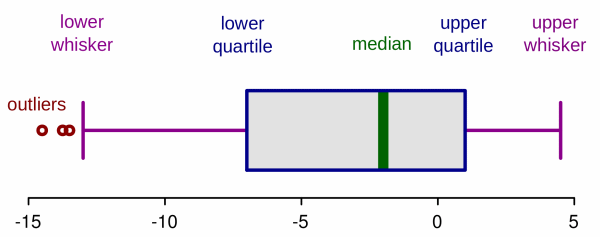 The bottom and top of the “box” (left and right above) are always the first and third quartiles, and the band inside the box is always the second quartile (aka, the median). The whiskers can be used to denote different things, but in this case I’ve opted for the simplest form: the minimum and maximum of all of the data points. I haven’t bothered with trying to pull out outliers.
The bottom and top of the “box” (left and right above) are always the first and third quartiles, and the band inside the box is always the second quartile (aka, the median). The whiskers can be used to denote different things, but in this case I’ve opted for the simplest form: the minimum and maximum of all of the data points. I haven’t bothered with trying to pull out outliers.
For most of the reviewers in my database, I have plotted below the distribution of all of their personal scores. For this presentation, I have put the reviewers in random order, identified only by a single letter. I have also included a “Users” group for all the whiskies in my database that have received a user score on the popular wine-searcher.com website. Despite its name, this is also a great resource for those wanting to assess the relative cost of whiskies in their local area, relative to other parts of their country or internationally.

What is the first you notice about the absolute value of reviewer scores compared to the wine-searcher.com users?
That’s right, the users on wine-searcher tend to score the whiskies they rate much higher than those the expert’s choose to review (i.e., the median score for the Users is higher than most expert reviewer subsets). You will notice that the quartile box size of the User scores is narrower than most of the expert reviewer scores (i.e., the User scores are also less variable than the experts, as well as higher on average).
But it is even more of a disparity than it appears above, as the quality of whiskies scored is not the same across groups. As a proxy, the typical median whisky price for most of the expert reviewers above is ~$70 a bottle. But for the Users group above, the median whisky price is ~$55. I will discuss the relationship between price and quality later, but this does suggests that not only are the Users rating their whiskies higher (in absolute terms), but they are rating lower quality whiskies to start with (i.e., the relative difference to expert reviewers is even greater).
Reviewer Selection
This brings me to how I selected my so-called expert reviewers. After exploring a large number sources, I have settled on >25 reviewers who have demonstrated an extensive array of tasting experience. Most of these have reviewed hundreds to thousands of whiskies, and so have meaningful experience in trying to classify and rank them. In some cases I have selected reviewers with a narrower publication list, due to their area of specialization (e.g. some dedicated Canadian of Japanese whisky specialists). Most of these are online bloggers/reviewers (as the data is easier to access), but some well known print ones are also included. All the reviewers are all still currently active, which is an important criteria (i.e., they are reviewing modern expressions that are still available for you to buy). Please see my reviewers page for more info.
I will get into the differences between expert reviewers when I discuss how I normalize and equalize my Meta-Critic scores in the next installment of this methodology section.
This is Dope. That part about the two whiskeys probably had me laugh out loud. Thanks for this. I’ll be back here to check in on the results