

Methodology – Modern Malt Flavour Map
Following from the discussion of the early attempts at flavour classification, it is time now to explain how you can work from flavour component scales to build a scientifically-validated classification scheme for malt whiskies.
When starting from scratch, this is a very labour intensive process. It involves extensive data collection, as the number of category scales needed are significant, and the data must be drawn from an extensive range of expert reviewer sources. It also requires editorial judgement, as experts seldom agree on everything. But once collated and properly curated, a proper cluster analysis of core flavour profiles can be performed, and validated against the underlying dataset. This dataset is ultimately be based on the frequency and/or qualified intensity of a controlled vocabulary lexicon among reviewers.
Some people will argue at this point “but every whisky has a unique flavour, you can possibly classify them”. It is true that at a sufficient level of detail, each whisky is unique. But the same can be said for every natural process or living thing in this Universe, and yet we still regularly classify things into major categories. The question is whether or not you have a proper objective evidence base for the classification, or if it is simply ad hoc and personal. If you are working from enough category scales, with enough gradations per scale (both properly validated), then you should be able to statistically pull out valid major categories from the data.
The point here is to see the forest for the trees, not focus on the shape of an individual tree. And to do so in a way that is rigorously supported by evidence, not intuitive “feel”. In the end, this will give you a way to navigate the major byways of whisky flavour, to help you find those really interesting individual trees. 🙂
Cluster Analysis
Clustering is actually a well-established area of statistical modeling. It is widely used in biology and psychology research, but can be applied to just about anything with data to segment and mine (i.e., everything from the phylogenetic relationships between plants to categorizing people’s fashion choices). It allows us to pull out interesting subsets of data based on how similar or different certain subgroups are from others in the whole set. And best yet, the validity of these methods can themselves be examined statistically, to determine the validity of the approach and the results.
A fun recent example of clustering is a statistical analysis of the core elements in the paintings of Bob Ross (he of the “almighty mountains” and “happy little accidents” on the frequently re-run PBS show, the Joy of Painting). 🙂
Principal Component Analysis (PCA)
Of course, reducing a large number of category scales into a (somewhat) smaller number of clusters is only so useful in characterizing flavour profiles. After the cluster anaylsis is done, a principal component analysis (PCA) can then be used to determine which characteristics explain most of the variance in the clusters, narrowing down the information into more manageable comparisons. Basically, you can think of a PCA as a means to reveal the underlying structure of the data, in a way that best explains the variance. In practical terms, it is often used to reduce a large number of dimensional scales into something more manageable, if that reduction is supported by the variance in the data.
Although it is a lot of work to do, the extensive range of information already available on whiskies suggests that a cluster analysis followed by PCA is certainly feasible – and would likely yield relevant and justifiable results. Fortunately for me, someone has already done exactly this. Building on the earlier work I described in whisky flavour component development, Dr. David Wishart of the University of St Andrews has created a detailed modern flavour profile of single malt scotch whiskies – based on clustering and PCA.
You can learn more about the specific system developed by Dr. Wishart in his 2009 article in the journal of the Royal Statistical Society Significance: Volume 6, Issue 1, pages 20–26, March 2009 (DOI: 10.1111/j.1740-9713.2009.00337.x). It is also well covered (in more layman language) in his excellent book Whisky Classified.
This existing example provides a great deal of reassurance that the fundamental approach is valid – and also means I don’t have to re-invent the wheel of a new controlled lexicon and validation. Instead, I have adopted and revised the existing Wishart’s classification system for flavour. In particular, I am using his clusters as the starting point to expand on a wider range of whiskies (and reviewers). As we will see, this flavour mapping also provides a valuable anchoring point on which to overlay my novel whisky quality-metric meta-analysis. I am hoping to create a full cluster analysis for Canadian whiskies from core categories at some point, but that will have to wait until I have more time. For now, the flavour profile analysis here will remain limited to scotch-style whiskies.
Wishart Flavour Analysis
In the Wishart analysis, earlier flavour classification systems were re-formulated into 12 “cardinal flavour” categories (i.e., core components). Each of these was assigned a score on a 5-point scale, representing the intensity of each flavour. This was based on the curated reviews of a small panel of expert whisky reviewers. He then sent the ratings around to wider number of whisky industry members for their feedback and refinement. This step was important, as there is a large element of personal judgement required in deciding the final scores for each whisky in each category. But as a result, he can make the case that his flavour categories and scores have the tacit approval of the wider Scottish Whisky Industry.
He then ran a cluster analysis and developed a 10 cluster classification, which he simply labelled alphabetically (i.e., custers A-J). The cluster analysis is based on the popular k-means clustering method, with apparently some adjustment to the focal point for more efficient serial re-ordering of the resulting tree.
Whether its due to the clustering algorithm or the selection of core component ratings, his method certainly seems to produce a much better outcome than any of the earlier attempts I’ve seen published.
From there, he ran a PCA to identify the key factors that determine flavour. Although four factors were found to be statistically significant, nearly 50% of the variance in the data could be explained by the following two factors: winey-smokey flavour, and delicate-rich intensity. This allows you to essentially collapse 12-dimensional space into 2-dimentional space (which is helpful for those of us who are not string theorists in Physics departments). 😉
Let’s see what you get if you plot the whiskies in his 10 clusters on a 2-dimentional grid of these two key factors (shown below for the whiskies that overlap in my dataset, color-coded for cluster).
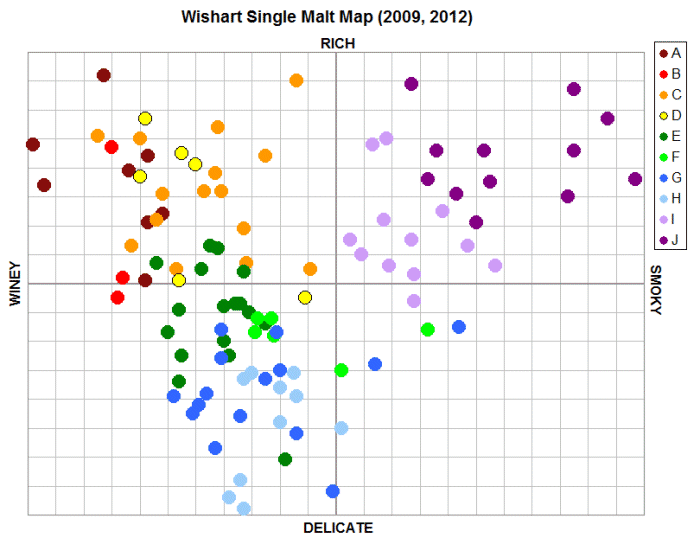 Anyone with stats experience would likely be suspicious of the pattern to the data above (i.e., the distinctive “V” shape). For normally-distributed datasets, any clear secondary pattern on a chart of the main scales from the PCA would suggest that you haven’t accounted for all the key sources of variance. But this was expected. As Wishart describes, the next significant factor related to cereal/malty and tobacco/herbal notes in the whiskies (and thus likely discriminates young whiskies from those with extensive barrel aging). The fourth significant factor related to degree of spicy/sweet notes in the whiskies.
Anyone with stats experience would likely be suspicious of the pattern to the data above (i.e., the distinctive “V” shape). For normally-distributed datasets, any clear secondary pattern on a chart of the main scales from the PCA would suggest that you haven’t accounted for all the key sources of variance. But this was expected. As Wishart describes, the next significant factor related to cereal/malty and tobacco/herbal notes in the whiskies (and thus likely discriminates young whiskies from those with extensive barrel aging). The fourth significant factor related to degree of spicy/sweet notes in the whiskies.
However, nearly half of the variance is explained by the first two factors shown in the chart above. The third factor only accounted for an additional 10% of the variance, with another 9% for the fourth factor (all other factors were not statistically significant). Given these results, I agree with his conclusion that the chart above can be described as the best 2-dimensional view of the flavour profiles of the whiskies in his analysis.
As a reminder (discussed previously), whisky is an engineered product. There is no reason to assume that whisky flavours are evenly distributed across the possible spectrum of flavours. Indeed, all experience suggests quite the opposite – distillers purposefully craft blended products that appeal to the specific flavour preferences of the consumer. At the end of the day, this flavour comparison chart (based on the PCA of the cluster analysis of the properly curated detailed categories) represents the best known map of whisky flavour.
Methodological Limitations
That said above, I should clarify that like all statistical methods, cluster analysis and PCA both have their inherent limitations.
Different algorithms (clustering methods) will produce different final clusters, given the specific way groups are merged in the analysis. All clustering approaches are dependent on the starting conditions of the analysis (i.e., the way the variables are ordered). And so, with the introduction of additional data over time (i.e., adding more whiskies in this case), the specific assignments of each whisky within the clusters can change.
PCA is dependent on the scaling of the variables, and on any inherent assumptions in the dataset. In other words, you are only as good as your underlying dataset (i.e., the 12 cardinal scale assessments of each whisky in this case). On that front, the Wishart data collection is by far the most extensive and well validated that I have encountered.
In any case, properly constructed clustering analyses can provide the most useful way to segregate out true patterns in complex datasets.
Updating and Expanding the Analysis
For the purposes of the analysis on this site, I have reviewed the final assignment of over a hundred whiskies in the clusters identified by Wishart (present in my database, as still commonly available today). Rather than recreate the original 12 cardinal scales and scores, and re-do the clustering analysis, I have chosen to start from his final 10 flavour clusters and Principal Component Analysis (PCA).
On reviewing the detailed Wishart cluster data, and comparing to the lexicon used by the extended range of reviewers in my sample, I found a small number of whiskies whose flavour cluster assignments required revision. Typically, these were whiskies whose precise alignment in the PCA showed significant overlap with a neighboring cluster anyway (i.e., the overlapping cluster was a better fit for the descriptions from my panel of expert reviewers). As such, about half a dozen whiskies have been re-assigned to neighboring clusters.
Similarly, I found little justification for maintaining flavour cluster “D”, which had relatively few whiskies assigned to it in my dataset – and where the PCA showed two distinct subgroups that were completely overlapped by the neighboring clusters C and E. As a result, the additional half dozen D cluster whiskies were re-assigned to C and E, as most appropriate. Finally, I have expanded the range of cluster assignments for additional whiskies not available during the earlier Wishart analyses, as well as some international whiskies that have a single-malt flavour profile (again using the descriptions by my panel of expert reviewers as a guide).
In terms of the original whiskies analyzed by Wishart, here is a revised chart showing how they relate in my analysis:
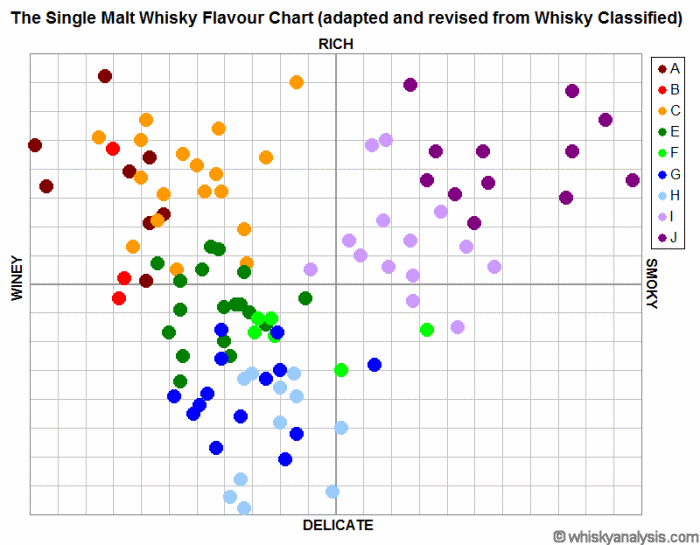 This chart is the best 2-dimensional description of the final flavour clusters for the whiskies in my dataset that overlap with the Wishart analysis.
This chart is the best 2-dimensional description of the final flavour clusters for the whiskies in my dataset that overlap with the Wishart analysis.
The individual Clusters could be described as follows (with select examples):
- A – Full-bodied, sweet, pronounced sherry – with fruity, honey and spicy notes (e.g., Aberlour A’Bunadh, Auchentoshan Three Wood, Glenfiddich 15yo, Glendronach 12yo, Glenmorangie Lasanta)
- B – Full-bodied, sweet, pronounced sherry – with fruity, floral and malty notes, some honey and spicy notes may be evident (e.g., Balvenie New Wood 17yo, Glenfarclas 10yo/15yo/17yo, Glengoyne 17yo/21yo, Penderyn Madeira)
- C – Full-bodied, sweet, pronounced sherry – with fruity, floral, nutty, and spicy notes, some smoky notes may be evident (e.g., Aberlour 10yo, Glenfarclas 105/12yo/21yo/25yo/30yo, Glenmorangie Signet, Highland Park 18yo)
- E – Medium-bodied, medium-sweet – with fruity, honey, malty and winey notes, some smoky and spicy notes may be evident (e.g., Auchentoshan 12yo/18yo, Dalmore 12yo, Glenrothes Select Reserve/Vintage 1989/1991/1992/1994, Old Pulteney, Redbreast 12yo)
- F – Full-bodied, sweet and malty – with fruity, spicy, and smoky notes (e.g., Bunnahabhain 12yo, Deanston 12yo, Glen Garioch 10yo/12yo/15yo, Glenlivet French Oak 15yo, Tobermory 10yo)
- G – Light-bodied, sweet, apéritif-style – with honey, floral, fruity and spicy notes, but rarely any smoky notes (BenRiach 12yo, Bruichladdich Laddie Classic, Glenfiddich 12yo, Glen Garioch Founder’s Reserve, Glenmorangie 10yo, Jura 10yo)
- H – Very light-bodied, sweet, apéritif-style – with malty, fruity and floral notes (e.g., Auchentoshan Classic/10yo, Cardhu 12yo, Dalwhinnie 15yo, Glen Grant 10yo, Tamdhu 10yo)
- I – Medium-bodied, medium-sweet, quite smoky – with some medicinal notes and spicy, fruity and nutty notes (e.g., Ardmore Traditional Cask, BenRiach Curiositas 10yo, Bowmore 12yo, Highland Park 12yo, Jura Superstition, Oban 14yo, Talisker 10yo).
- J – Full-bodied, dry, very smoky, pungent – with medicinal notes and some spicy, malty and fruity notes (e.g., Ardbeg 10yo/Corryvreckan/Uigeadail, Lagavulin 16yo, Laphroaig 10yo/15yo/18yo/Quarter Cask, Toumintol Peaty Tang)
Please see the Whisky Database for further examples of each class.
Value of Super Clusters
This chart (and its underlying PCA) also provides a good basis for the formation of “Super Clusters” that combine neighboring clusters with a high degree of overlap (i.e., similar flavour profiles). Wishart himself had proposed specific sets of combined clusters when trying to perform a structured tasting (specifically, along groups of 6 and 4 sets of clusters). My own assessment is similar, with 5 recommended “Super Cluster” groups:
- A, B, and C
- E and F
- G and H
- I
- J
Note that I do not recommend combining I and J, given the wide range of smokey flavours present. Also, you need to recognize the potential for overlap between neighboring clusters near the margins (e.g., between F and I, or C and E).
By default, I have sorted the whisky data on this site by “Super Cluster” when comparing meta-critic scores. Of course, you are free to re-sort the data however you please. For further information on how to the interpret the data table, including text descriptions of the clusters and super-clusters, please see my discussion here.
It is now time to explain how my novel Meta-Critic scores are constructed, and to further explore some of the interesting correlations and observations in the cluster analysis and PCA, as described on my Interpretation pages.
Further Reading
If you were to buy just one book on whiskies, I would recommend the latest printing of Dr Wishart’s Whisky Classified.
It is surprising to me that this book is not better known among whisky enthusiasts, but I imagine the statistical methodology is not something most people are familiar with. I suspect another reason is that Dr Wishart’s conclusions may not match the idiosyncratic classification systems certain reviewers have developed over their careers. After all, we all tend to trust our own personal intuitive systems – based on subjective experience – even over a more rigourous objective one. This is especially the case if we aren’t familiar with the methodology.
But all systems are open to examination, and as I describe here and on the subsequent Interpretation pages, the Wishart classification system for single malt flavour remains the most scientifically valid and accurate method currently available. It is a great starting point for the unique Meta-Critic quality analysis that I have completed, and the re-assignment of modern whiskies by flavour cluster.
Bourbon Classification
The situation for classifying bourbons and other American whiskies is a little different. Please see my more recent Bourbon Classification page for more info to the system I am using there.
Hi, I was looking for the Whisky Analyst program online. Since you have analyzed it more, I was hoping you have downloaded the program of have the raw data. Can you help me out?
Unfortunately no, I do not have the software or raw data. I have worked from published reports only.
The Wishart Cluster Map and your revised Cluster Map are particularly useful in visualizing where a particular whisky sits within the flavour spectrum.
Do you plan to include these graphics for each whisky in the database under the expansion drop down, or can you consider this, as it would be useful to assist individuals using this database to define their own personal sub-clusters if known personal favourites were tightly grouped in the map.
Yes, I’ve been thinking of adding this functionality – since I admit, as currently configured on the site, it is hard for the user to easily identify clusters. When I get the chance, I plan to at least add mouse-over functionality to the maps. Long-term, I would like to re-run and expand the analysis to other whiskies types … hard to find the time, however.
Hello! Awesome initiative.
I couldn’t find the description for clusters R0 to R4 for bourbons and rye whiskeys. What flavors do they refer to?
Thanks, and good catch! That’s a new classification system I’ve just developed for bourbon and American whiskies. I will be posting a new article shortly on how it works, but short version is that it is explicitly based on rye content (R) in the mashbill, with the number indicating the relative level. For reasons I will explain, this works as a pretty good proxy for classifying American whiskies.
Background page is now up: Bourbon Classification
We want to do a whisky-tasting -event within the family .
Most of the persons are not used , not familiair with whiskies/whiskeys, yet.
The help of “flavour maps ” for each of them to have in hand would be a great help to
get introduced in their own way, in their on speed, and in communication with each other etc.
Is it possible to have hand on
15 each of printed Flavour Maps
to hand out at the start of our event.??. Thank you very much for your answer.
My Address: C.M. Musters, Barietdijk 212, 4706 DE Roosendaal, The Netherlands.
You could certainly use the map here to help you select whiskies for your tasting (I recommend doing no more than 5 in one sitting). Check out my page here on Hosting a Whisky Tasting, available off the Background heading of the menu bar.
Although I do not produce flavour maps, I’m sure you could create something to provide your guests from the information distilled here.
Slainte!
The new single malt chart looks great do you have a copy with names associated with the dot?
Been meaning to getting around to updating with that functionality, just haven’t gotten to it yet.
Thx
There are some people who have such great taste bud who would immediately identify the quality of the whiskey. Unfortunately, I do not possess the same type of qualities.
Firstly, I’d like to thank you for making this information available. I found your website after reading David Wishart’s book and was really excited to see that you’ve revised and continued to extend the database that he started.
I’m personally less interested in the correlation between cost and score but rather the ratings of each whisky within the 12 (or 10 in your case) flavour categories so that I can find others that have more or less of a particular attribute. For example, I may have liked the smoky elements of an Oban 14 and would like to find similar whiskies that have an incrementally more peated element to them.
This data is available in Wishart’s book as ratings out of 5 in each category but in your database it is omitted or obscured by the less granular classification of each whisky into a cluster. When composing your database do you still rate each whisky on a scale in each category and would that be information you’d be willing to share?
Many thanks an keep up the great work,
Luke
Thanks for the comments Luke. I have not extended Dr Wishart’s work in terms of capturing the ordinal scale data for each whisky flavour component (that underpins his cluster analysis). Instead, I have focused on matching new whiskies to the existing clusters using a controlled vocabulary, rather than trying to recreate the clusters from his original scales. In addition to the (extensive) work that would be involved in recreating and extending his raw data methodology, it is unlikely that a new cluster analysis would produce exactly the same groupings. But unfortunately, this means that I am not able to provide that level of granularity. My focus has been instead on the reviewer statistical normalization and integration for this site.
I have Wishart’s book and I really like your analysis. I have a minor issue though with the winesmoke axis. The sherried peat style has become very popular (eg uigedail and many more) and these whiskies can be both heavily peaty and prominently winey. Have you considered adjusting the clusters to distinguish this style? Currently all heavily peated whisky is in a single cluster. I suppose none of the original profiled malts was of this type though except perhaps lagavulin.
Thanks for the comment. Yes, the heavily peated cluster does lack resolution when it comes to heavy winey influence. But that is simply a limitation of the clustering method – the two axes only account for about half the overall variance, so there are limitations with the 2-D plot at the extremes. This is revealed most clearly in the case of the both winey and peaty whiskies, which typically get reduced to the C-cluster (as intermediate to the extremes). But heavy peaty seems to overwhelm in the clustering analysis, keeping them in J (i.e., Lagavulin). The best I can do is recommend that people check out the reviews to assess the level of winey-ness on heavily peated whiskies.
I recently acquired copy of “Iconic whisky” by Mald and Vingtier, English Language copyright 2016. The subtitle is”Tasting Notes and Flavour Charts for 1000 of the World’s Best Whiskies”. They use a pie chart type of graphic that shows Nose, Taste and Finish by type and magnitude and gives an overall rating 1-9. There is a very helpful aroma wheel with the associated descriptions. There is a little misalignment between their ratings and your database but not glaring. I found the book helpful with putting names to the aromas and taste that I couldn’t accurately describe.
Thanks for the heads-up, I wasn’t familiar with that book.
I’m trying to reconcile your/Wishart’s dimensions of DelicateRich & WineySmoky with the other common map, which uses DelicateSmokey & LightRich. Are there equivalent dimensions in these two systems (meaning I can convert one map the other via relabelling dimensions or transposing) or are they different?
No, as that other map you are referring to is not based on validated criteria, and suffers from numerous methodological and graphing issues. I discuss the problems with it here:
https://whiskyanalysis.com/index.php/background/early-attempts-at-flavour-classification/
I just held a whisky tasting event last night, and your flavor map and database was wonderfully useful, allowing to sample from each supercluster. Thank you!
I would love to be able to generate a chart that showed each of the whiskies we tasted on the 2D map, but the databased just identifies the cluster, not the actual X/Y coordinates on the map. Is that information available? Better yet, have you considered an online tool to generate a map for a set of whiskies from the database?
I’m sure people would also like that for creating a flavor map of their home collections!
Unfortunately no. Actual x/y coordinates would depend on re-creating the actual principal component analysis and cluster analysis, with comparable raw data on each of the 10 independent rating scales. This isn’t feasible, so the assignment to a cluster is based on a post-hoc comparison of terms in reviewers (relative to the original Wishart analysis), which is the best I can do right now.