

Methodology – Meta-Critic Score
To explain the nature (and value!) of the scientific meta-analysis used here, I need to begin by clearing up a few common misunderstandings around whisky reviewer scoring.
Quality Ranking
As I explained in my earlier methodology article on Reviewer Scoring, assigning scores is simply a way to order and rank the relative quality of products being reviewed.
It is commonly believed that whisky preference is simply too individualistic to be amenable to any sort of coherent analysis. Personal taste/smell preference is so unique (or so the thinking goes) that the best you can hope for is to try and find someone who is a relatively good match for your personal tastes. As you will see in the statistical analysis below, it turns out that this assumption is wrong.
Of course, even if there were some underlying consistency in how individuals ranked whiskies, you could argue that the variation in how they score would make that impossible to detect. But that last bit is actually something you can control for. It’s a fundamental truism that all data is composed of pattern and noise (i.e., data = pattern + noise). The goal of inferential statistics is to remove only the noise from the data, revealing the underlying pattern.
Now, that might sound easy, but it is in fact exceedingly difficult (for the reasons outlined on my earlier methodology pages). Fortunately, there have been many decades of focused thought on how exactly to accomplish this goal – and to verify the accuracy of the ultimate results.
But before we get into that, a fundamental question remains – are reviewer scores even comparable to one another to start with? In the language of statistics, we refer to this as correlation – do whisky reviewer’s score correlate well with one another? In other words, does knowing how one reviewer scores help you predict what others (yourself included) will think of those whiskies?
Correlation Analyses
A correlation analysis is easy to perform, and is usually pretty disappointing in this case. A good example is the one posted by John and Raph of Cask Tales, where they compared their own rankings to those of well-known whisky reviewer Jim Murray. See the link above for the actual graph, but to quote from that page on the results of the correlation:
In short, there was none.
(In long, there is actually a slight positive correlation, with a coefficient of determination of 0.1021, suggesting that – in a purely statistical sense – about 10% of the mark we give a whisky could be predicted by knowing the mark that Jim Murray gave it. Or, to put it another way, telling you absolutely nothing, other than that we don’t agree particularly much. See why I kept it short?)
This would seem to be pretty definitive (at least as far as Cask Tales is concerned). Intuitively, this would lead you to think that there is no point in trying to integrate all the scores of the various reviewers (including Mr. Murray). They would similarly each be too variable, with no real predictive value when grouped, you would think.
That intuition is wrong.
A key point here is that statistical reasoning is far from intuitive. When we look at data, our intuition often leads us astray. For one, people frequently see patterns in random data and then jump to all sorts of unwarranted conclusions. But we also miss meaningful connections because we cannot easily separate the noise from the pattern (recall my earlier point about to fundamental goal of statistics, also discussed here). Statistical rigour is needed to separate the “wheat from the chaff” and to explore the patterns in the data, if we are to draw valid conclusions.
Let me prove that to you in this case.
Discordant Reviewers
Note that the correlation data shown below are drawn from an earlier version of my database, when it was only 380 whiskies large (i.e., at the time of this site’s launch). I continually monitor the relationships in the data, and all the patterns below continue to hold at the same level. So you would see more individual data points if I were to re-run the graphs now, but the correlation coefficients would not change appreciably.
Here is a correlation analysis between the whisky scores for two well-known reviewers, Jim Murray of the Whisky Bible, and online whisky video blogger Ralfy Mitchell. At the time of this site’s launch, there were ~80 whiskies scored by both of these two reviewers.
 Just as in the case of Cask Tales, the correlation between Ralfy and Jim Murray is poor (the correlation coefficient, r, is only 0.18). This would lead you to think that there is no point in bothering with an integrated analysis including these reviewers. I will explain how I have done this analysis below, but let’s jump right to the punchline: if you could find a statistically valid way to integrate reviewer scores, how well would Jim Murray and Ralfy correlate to that meta-analysis composite score (what I call my meta-critic score)? I have managed to do just that, and have quantified how well each reviewer correlates to this properly normalized meta-critic score.
Just as in the case of Cask Tales, the correlation between Ralfy and Jim Murray is poor (the correlation coefficient, r, is only 0.18). This would lead you to think that there is no point in bothering with an integrated analysis including these reviewers. I will explain how I have done this analysis below, but let’s jump right to the punchline: if you could find a statistically valid way to integrate reviewer scores, how well would Jim Murray and Ralfy correlate to that meta-analysis composite score (what I call my meta-critic score)? I have managed to do just that, and have quantified how well each reviewer correlates to this properly normalized meta-critic score.
Let’s start by plotting Mr. Murray versus the normalized mean meta-critic score, followed by Ralfy, for all the whiskies in my dataset they have reviewed.

 Now there’s an interesting finding! Both reviewers correlate reasonably well with my normalized reviewer mean from the meta-analysis (r=0.58, 0.60). As an aside, these are actually two of the worse individual correlations to the overall meta-critic score – most reviewers correlate much closer (as we’ll see in a moment).
Now there’s an interesting finding! Both reviewers correlate reasonably well with my normalized reviewer mean from the meta-analysis (r=0.58, 0.60). As an aside, these are actually two of the worse individual correlations to the overall meta-critic score – most reviewers correlate much closer (as we’ll see in a moment).
But let’s stop to think about how counter-intuitive this finding is. Jim Murray’s and Ralfy’s whisky review scores correlate very poorly with each other. Note that any variation in how they apply their own scoring values doesn’t matter here (i.e., the absolute values don’t matter). A correlation simply looks at their relative consistency to each other. But despite this poor showing, both correlate fairly well with a normalized mean that is based in small part on their own scores. This almost seems like magic – but it in fact shows you power of a proper statistical analysis and comparison.
Consistent Reviewers
Now, you might think I’ve cherry-picked an anomalous example above. So let’s consider another case, from two reviewers that we would have every reason to expect to correlate well with each other. As I explain on my Reviewers page, the QuebecWhisky.com website is a fabulous resource on modern whiskies, with over 2000 profiled in the last four years. One of the great values of this resource is that multiple reviewers typically taste and score the same whiskies (apparently from the same bottles, according to the commentaries). The two most prolific reviewers on this site are André and Patrick, who have each reviewed over 1400 whiskies as of the time of my site’s launch. They overlap on most of these, providing contrasting scores and tasting notes. Given that they seem to be drawing on the same bottles – and are aware of each others’ reviews – it is reasonable to expect less variability between these two reviewers than just about any other pair of reviewers taken at random from the blogosphere.
So, how well do they correlate with each other on whiskies they have both tried, from my database?
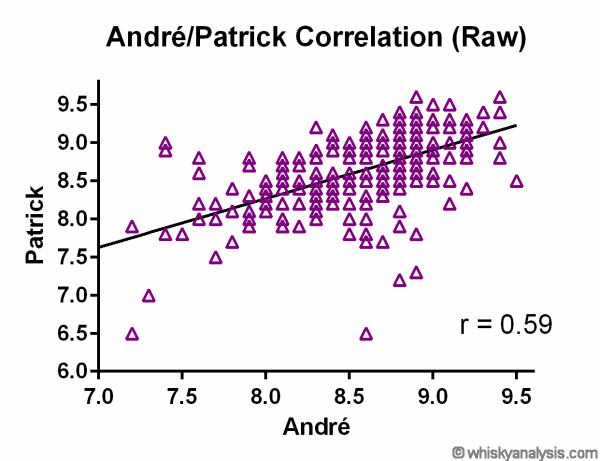 That’s pretty good, at r=0.59. There are clearly some whiskies where they differ in opinion, but on the whole, they show one of the strongest correlations I’ve ever seen between any two whisky reviewers.
That’s pretty good, at r=0.59. There are clearly some whiskies where they differ in opinion, but on the whole, they show one of the strongest correlations I’ve ever seen between any two whisky reviewers.
As an aside, the above graph is based on their raw scores, inputed directly from the QuebecWhisky.com website. What happens instead if I do a correlation of their normalized scores, after construction of the meta-analysis here?
 Absolutely nothing, as you would expect. Again, a correlation analysis is simply showing you how well they relate to each other, for each whisky. Normalizing their individual scores across the wider dataset should have no impact on this correlation, which is clearly the case above. This is an important control, to demonstrate that the meta-analysis is not distorting their relative rankings in any way.
Absolutely nothing, as you would expect. Again, a correlation analysis is simply showing you how well they relate to each other, for each whisky. Normalizing their individual scores across the wider dataset should have no impact on this correlation, which is clearly the case above. This is an important control, to demonstrate that the meta-analysis is not distorting their relative rankings in any way.
So, given that they already correlate reasonably well to each other, how do these two reviewers do against the overall meta-critic scores? Is there any value to this meta-analysis?

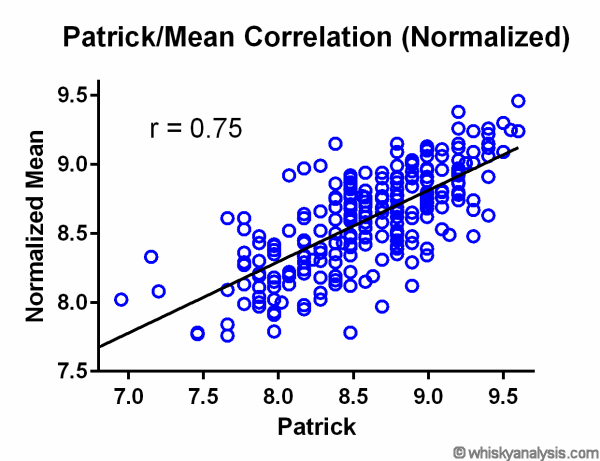 And so there is – they both cases, they correlate better to the overall meta-critic score than they do each other (i.e., r=0.76, 0.75 is better than r=0.59).
And so there is – they both cases, they correlate better to the overall meta-critic score than they do each other (i.e., r=0.76, 0.75 is better than r=0.59).
These results should give you a lot of confidence in accepting the overall meta-critic score as a likely good indicator for your personal preferences. And as it turns out, it is in fact better than any individual reviewer is likely to be – as I will explain below.
Summary Correlations
The above examples just serve to illustrate the general principles. What you really want to know is how well do all the reviewers do in this analysis?
As you might expect, each reviewer doesn’t correlate particularly well to any other given reviewer. There are exceptions of course – especially among reviewers who are keenly aware of each other’s scores (like some of the QuebecWhisky guys shown above). But if you do a proper correlation analysis – with either Pearson or Spearman correlations, looking at only statistically significant correlations between all reviewers (i.e., sufficient overlap of whiskies reviewed) – you will find that the typical reviewer correlates somewhere ~0.40-0.45 to any other given reviewer.
Again, that’s likely to be an over-estimate of the typical correlation between reviewers, since we know several of them in my dataset are not truly independent from one another. As expected, the variation among any two reviewer correlation pairs is high – they actually range from 0.20 to 0.85 between any two given reviewers. But typically, most reviewers correlate poorly with one another.
What is truly impressive here is that the average correlation of each of the reviewers to my properly-validated meta-critic score is ~0.73. The variance is similarly low (i.e., each reviewer correlates to the meta-critic score somewhere between 0.55 and 0.85). This means that despite the fact that reviewers typically don’t correlate well with each other, they all correlate reasonably well with the meta-critic score developed here. And these summary results have continued as more reviewers and whiskies have been added to the database.
Indeed, across the >20 reviewers used in this initial analysis, there was only one case where a reviewer correlated better with another reviewer than he did with the overall meta-critic score. And in that case, the difference was marginal, with the meta-critic score coming a very close second. It was also not reciprocal – the reverse correlation was still lower than the meta-critic score for the other reviewer (i.e., the other reviewer still correlated better to the meta-critic score than he did to this one individual).
I have to say, I was somewhat surprised by these findings. Of course, I had expected there to be significant value to the meta-critic scoring approach (after all, it’s a big part of why I spent months compiling and verifying all the data). But I intuitively still expected to find reviewers who consistently correlated better with each other than they did with the meta-critic score. And so, by extension, I expected to find reviewers who correlated better with my personal preferences. 😉
On this front, there is one reviewer with whom I correlate better with than I do with the overall meta-critic score – and it isn’t the reviewer I expected it to be. Again, so much for the value of intuition! The point to the above analysis is that it is not actually worthwhile to try find some arbitrary reviewer who is strong personal match to your preferences. You are better off relying on the combined meta-critic score of all normalized reviewers, as the evidence shows that this is consistently the best match (at least among the most prolific reviewers).
Creating the Meta-Critic Score
Ok, so how did I create this meta-critic score? Let me start by showing going back to that box-and-whisters plot (explained earlier) showing how variable each reviewer is in their personal scoring. Rather than identify the reviewers at this point, I’ve given each one a letter designation.
 Ok, there are certainly a lot of differences in how reviewers score. But as I explained in my earlier Understanding Reviewer Scoring, a big part of this is simply variation in how they choose to apply the number scale (i.e., how wide a set of scores, with what sort of typical scores). Reviewers K and O above are known for reviewing an extremely wide range of whiskies (from budget to expensive) – but clearly differ in the range of actual scores they give. Reviewers C and N are at another extreme – both very restrictive in the range of scores they give, but again have picked different parts of the typical scale range.
Ok, there are certainly a lot of differences in how reviewers score. But as I explained in my earlier Understanding Reviewer Scoring, a big part of this is simply variation in how they choose to apply the number scale (i.e., how wide a set of scores, with what sort of typical scores). Reviewers K and O above are known for reviewing an extremely wide range of whiskies (from budget to expensive) – but clearly differ in the range of actual scores they give. Reviewers C and N are at another extreme – both very restrictive in the range of scores they give, but again have picked different parts of the typical scale range.
Again, the differences explained above are just the “noise” – there can also be actual differences in the selection of whiskies they choose to review (i.e., the pattern). The problem is that any underlying pattern to this data is likely drowned out by the noise of their variation in scoring.
Normalizing Reviewer Scores
So, how do we remove the noise (i.e., the variation in how they apply an arbitrary scale) from the actual pattern (i.e., the difference in the quality of whiskies they choose to review)? If we just tried to average their raw numerical scores, we would likely just get garbage as a result. Similarly, if we just assumed they all reviewed the same quality of whiskies – and so, normalized their scoring so each had the same average score and distribution range (i.e., make all the box plots look the same) – then that too would also obscure the true patterns.
The solution is somewhere in-between. To start, I have built the database up over time, being mindful of how the distributions were falling out for each reviewer. I was therefore able to include a variety of whiskies in the database specifically to help ensure as normal a distribution as possible, for each reviewer. While this doesn’t let us just blindly normalize them all the same way, it does provide a good starting point. What I have done from there is used an iterative process for normalizing each reviewer’s scores, based on the whiskies they have reviewed.
There are many ways you can normalize datasets to allow further direct comparisons. A popular method that most people would be familiar with is percentile ranking (which is just a special case of quantile normalization). A percentile rank is often used when reporting the results of standardized tests (e.g., 80th percentile rank means you did as well or better than 80% of all people taking that same test). Percentile ranks also form a key part of the process when “grading on a curve.”
I have applied percentile ranking to the full database, and got a pretty good result (tested by correlation analysis for each reviewer). But I got a better result by computing so-called “standard scores“, better known Z-scores. One advantage to this approach is the dimensionless quality of Z-scores, which works well with my iterative method. It also produces a final transformed result which is easily interpretable by the reader, as you will see.
Z-scoring is a popular normalization method in stats, as it tells you how each score deviates from the overall “population” mean of that particular reviewer’s personal scoring. By converting each reviewer’s set of scores into Z-scores, I can use this information to regenerate individual scores against a new mean and variance. The key is selecting the right mean and variance for the larger true population of all reviewers.
If all reviewers had reviewed every whisky in the comparison, this process would be easy. You could just set a given mean and variance however you like – typically, the overall mean and standard deviation of the complete data set. You would then convert all the Z-scores for each reviewer into new transformed individual scores using this common set of metrics. That is not the case here, as reviewers select which whiskies they choose to review, and there are obvious (and potentially not so obvious) biases in those choices.
But this is none-the-less the first starting point to solving our problem. To begin, I started by normalizing all the Z-scores to the overall mean and standard deviation for all reviews. This was done only to get a “first pass” starting point for further analysis. This is certainly a much better starting point than the raw data. And a correlation analysis confirms a slightly better overall result than the percentile ranking normalization method.
The next step is to compare each reviewers first-pass normalized scores to all the other reviewers for only the same whiskies they have in common. This is the best way to get at patterns in the data – normalizing against the subset of whiskies that each reviewer has in common with the others. The resulting metrics – for each reviewer’s personal set of whiskies – varied, as you would expect (i.e., some whisky subsets had a higher or lower mean/SD than the overall population mean/SD of all whiskies). But these results served as a good “second-pass” point in the analysis. I then went back to the original Z-scores for each reviewer, and converted them using the new “regional” second-pass subpopulation means and standard deviations for that given reviewer’s subset of whiskies (incorporating all reviewers first-pass normalized scores).
The end result was a new set of specifically-adjusted scores for each reviewer. The overall population distribution that was slightly different from the first-pass normalization (as this second-pass is a combination of the all the specific reviewer subsets). I tested this new, more specific second-pass normalization result by correlation analysis, and got an even better overall match for each reviewer than the first-pass normalization.
I tried a third-pass normalization using the second-pass table as a starting point – but the end result was little changed from the second pass. Similarly, the correlation analysis showed no significant difference – suggesting the second-pass method above is more than sufficient.
Validating the Normalization Method
As an aside, I also tried doing this iterative method directly from the raw scores. But since the overall raw data of scoring is very variable, this method required several more iterations before it produced an equivalently good result (although it does get there in the end). I tried this several times when building my database, and it always needed at least 3-4 passes (when coming from the raw data) to produce as a good of an overall correlation as the second-pass method above from first-pass data normalized to the overall population mean/SD.
This is the nice part of iterative analyses – you can directly “measure” if this is improving the meta-score by doing a correlation analysis across all reviewers and seeing how well they correlate to the new normalization scores. Again, the reviewer’s correlations to each other will not change on these iterative passes – but their correlation to the combined meta-critic score is improved on the second iteration (using normalized scores) than it is on any the first pass measure.
To use an analogy, this method is kind of like curve-fitting analyses. You need to input reasonable starting values for key constants so that the computer has something to start from as it does integrative analyses to zero-in on the best fit line or curve. If you put in ridiculous starting values, the line (or curve) may never coalesce around the true best fit. But as long as you are in the general ballpark with your initial estimates, the computer will be able to calculate the most appropriate final set of constants this way. I am just fortunate that I didn’t need to do more than a few iterations. 😉
Let’s see how the box-and-whiskers look for each reviewer, after the iterative normalization method described above.
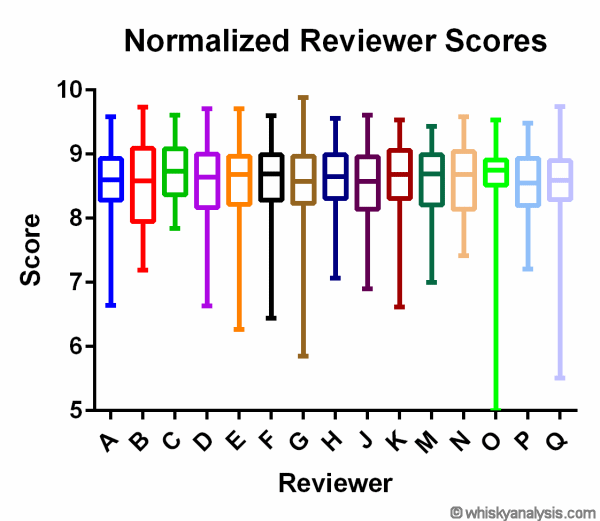 Well now, that’s a lot more similar! There are of course still differences between the reviewers – especially in the full range of scores given (i.e., whiskers), and their overall medians and quartiles. These differences now largely reflect the true “pattern” differences in which whiskies those reviewers have chosen to review. The “noise” of how they selected their score scale range has been mainly removed.
Well now, that’s a lot more similar! There are of course still differences between the reviewers – especially in the full range of scores given (i.e., whiskers), and their overall medians and quartiles. These differences now largely reflect the true “pattern” differences in which whiskies those reviewers have chosen to review. The “noise” of how they selected their score scale range has been mainly removed.
At the end of the day, the proof is in the pudding, as they say. Even if you don’t understand what I am talking about above, the correlation analyses presented earlier speak for themselves. This iterative method of combining the scores of >20 reviewers across 380 whiskies – using Z-score normalization applied to the specific subset of whiskies reviewed by each reviewer – has worked out even better than I could have hoped for (or intuitively predicted). It has managed to produce a combined meta-critic score that correlates better with each reviewer’s preferences than virtually any other individual reviewer could. To my knowledge, this is the first time this has ever been demonstrated for whisky reviewing.
But it is also only a first step. 😉
How to Interpret the Meta-Critic Scores
For those who have read this far, I can see you now exclaiming “WHAT!?!”. Surely this is good enough to allow us to decide which are the “best” whiskies, right? Not quite.
What we now have is a properly set of calibrated scores, consistent across reviewers. But how do we apply that across different classes of whiskies? For that, you need to do a proper flavour assessment of whiskies, using the statistical principles of cluster analysis and principal component analysis – as described on my Modern Flavour Map.
After that discussion, you can head over to my Interpretation pages for an explanation of how to put all this information together.
Pingback: Grading Whiskies Out Of 100: A Composte – jasonbstanding.com